+86 021-34206484
jz.TdLeelib@sjtu.edu.cn
登录
注册
项目登记
首页
Home
关于基金
About
基金简介
大事记
管委会介绍
䇹政要闻
Events
䇹政数据
Data
䇹政学者
䇹政导师
䇹政项目
Projects
联系我们
Contact
项目管理
Management
北京大学
复旦大学
兰州大学
苏州大学
台湾清华
上海交大
新闻
2024/12/16 15:21:33
sjtu_admin
往届学者在哪儿丨往届䇹政学者洪凌屹在计算机视觉领域的3项成果
䇹政学者、计算机科学技术学院2022届本科毕业生洪凌屹在攻读博士期间已经以第一作者在计算机视觉的顶会上发表论文3篇,其中包括:CVPR,ICCV,ACM MM。今天,FDUROP介绍洪凌屹的这3项学术成果。
䇹政学者洪凌屹
洪凌屹,2018年毕业于上海市崇明中学,考入复旦大学计算机科学技术学院,2022年6月毕业,目前在计算机科学技术学院张文强研究员的指导下攻读博士学位。该生于本科期间曾在张巍副教授指导下完成一项䇹政项目,获得“䇹政学者”称号,并以䇹政项目的成果在中国计算机学会推荐的A类学术期刊《IEEE汇刊-图像处理》上发表一作论文。
LVOS:长视频目标分割基准
现有的视频目标分割(VOS)基准测试主要集中在持续时间仅为 3-5 秒的短期视频上,而且大部分时间物体都是可见的。这些视频在实际应用中的代表性较差,而长期数据集的缺乏又限制了 VOS 在现实场景中应用的进一步研究。因此,我们在本文中提出了一个名为 LVOS 的新基准数据集,该数据集由 220 个视频组成,总时长为 421 分钟。据我们所知,LVOS 是第一个注释密集的长时 VOS 数据集。LVOS 中的视频平均时长为 1.59 分钟,是现有 VOS 数据集中视频时长的 20 倍。每个视频都包含各种属性,如长时消失重现和跨时空物体相似。在 LVOS 的基础上,我们对现有的视频对象分割算法进行了评估,并提出了由三个互补内存记忆组成的多元动态内存网络(DDMemory),以充分利用时间信息。实验结果表明了现有方法的优缺点,为进一步研究指明了方向。
图1 LVOS数据集示例
论文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Hong_LVOS_A_Benchmark_for_Longterm_Video_Object_Segmentation_ICCV_2023_paper.pdf
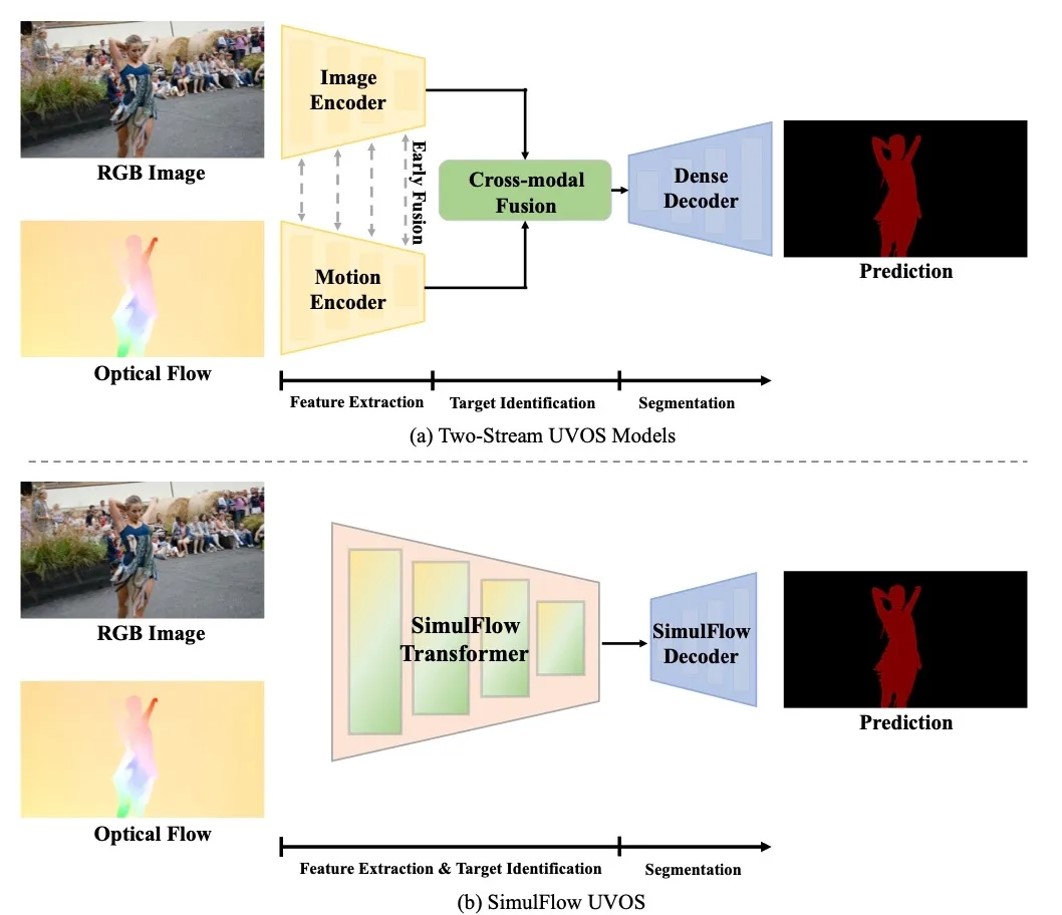
SimulFlow:特征提取与目标识别协同的无监督视频目标分割
无监督视频目标分割(UVOS)的目的是在没有任何人工干预的情况下检测给定视频序列中的主要物体。现有的大多数方法都依赖于双流架构,分别对外观和运动信息进行编码,然后再将它们融合在一起,以识别目标并生成对象掩码。然而,这种模式的计算成本很高,而且由于难以正确融合两种模态,可能导致性能不理想。在本文中,我们提出了一种名为 SimulFlow 的新型 UVOS 模型,它能同时执行特征提取和目标识别,从而实现高效的无监督视频对象分割。具体来说,我们设计了一种新颖的 SimulFlow 注意机制,利用注意力操作的灵活性将图像特征和运动特征融合在一起,其中每个阶段根据融合特征预测出的粗掩码用于将注意力操作限制在掩码区域内,并排除噪声的影响。由于 SimulFlow Attention 中视觉特征和光流特征之间是双向信息流,因此不需要额外手工设计融合模块,我们只需采用一个轻量的解码器来获得最终预测结果。我们在多个基准数据集上评估了我们的方法,并取得了最先进的结果。我们提出的方法不仅优于现有方法,还解决了双流架构带来的计算复杂性和融合困难。我们的模型在 DAVIS-16 上实现了 87.4% 的 J&F,速度最快(在 3090 上达到 63.7 FPS),参数最低(13.7 M)。我们的 SimulFlow 在视频显著物体检测数据集上也取得了具有竞争力的结果。
图2 SimulFlow示意图
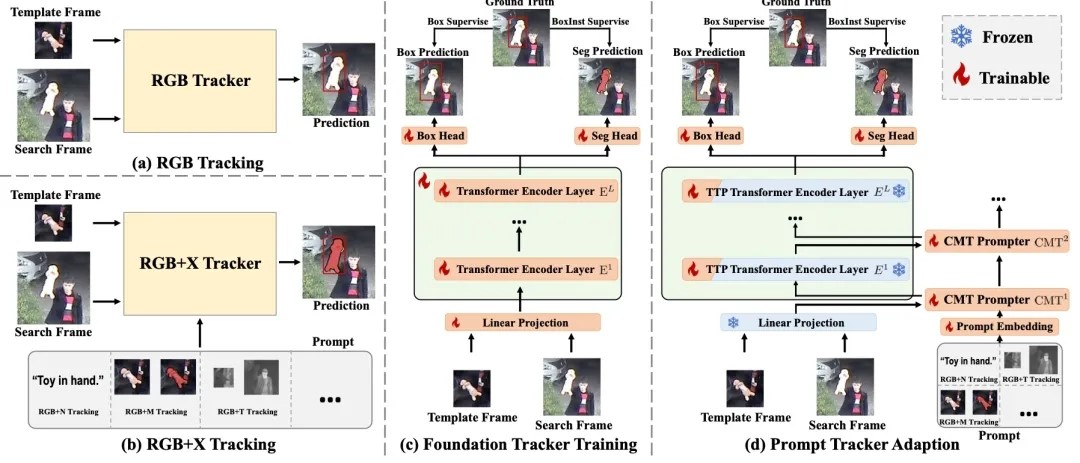
OneTracker:基于基础模型和高效微调的统一目标跟踪
视觉目标跟踪的目的是根据第一帧中的初始外观定位每帧的目标物体。根据输入模式的不同,跟踪任务可分为 RGB 跟踪和 RGB+X (如 RGB+N 和 RGB+D)跟踪。尽管输入模式不同,但跟踪的核心是时间匹配。基于这一共同点,我们提出了一个统一各种跟踪任务的通用框架,称为 OneTracker。OneTracker 首先在名为基础跟踪器的 RGB 跟踪器上进行大规模预训练。这一预训练阶段使基础跟踪器具备了确定目标物体位置的稳定能力。然后,我们将其他模态信息视为提示信息,并在基础跟踪器的基础上建立提示跟踪器。通过冻结基础跟踪器并只调整一些额外的可训练参数,提示跟踪器继承了基础跟踪器的强大定位能力,并在下游 RGB+X 跟踪任务中实现了参数高效微调。为了评估由基础跟踪器和提示跟踪器组成的通用框架 OneTracker 的有效性,我们在 6 个跟踪任务11 个基准数据集上进行了大量实验,结果显示 OneTracker 的性能优于其他模型,达到了最先进的水平。
图3 OneTracker
论文链接:https://arxiv.org/abs/2403.09634
来源:公众号-复旦FDUROP